
1 map
1.1 map 的实现
1.1.1 map 的底层结构
Go 语言使用的是哈希查找表,用链表解决哈希冲突。
在源码中,map 基于 hmap 实现,定义如下:
| |
其中 buckets 是指针,指向的结构体 bmap 称为桶,定义如下:
| |
每个桶最多能够容纳八个 k-v 对,其中 key 与 value 是分开存放的,为了免去地址对齐,节省空间。

1.1.2 map 的创建
调用 makemap 函数,进行 hmap 的初始化,计算各种字段,设置 hash 种子等,返回 *hmap 指针,map 在程序中以指针的形式存在。
1.1.3 hash 函数
_type 结构体中的 alg 字段与 hash 有关,指向如下结构体:
| |
typeAlg 包含两个函数,分别表示 hash 的计算和比较。_type 会根据 key 的类型分配对应的 hash 与 equal 函数。
1.1.4 key 定位过程
- key 值经过 hash 计算得到 64 bit 的结果。
- 低 5 位指示应在存放的桶序号。
- 高 8 位指示在桶中的位置,匹配 Hash top。
- 如果找不到,且 overflow 不为空,可以去 overflow bucket 中继续查找。
| |
b 代表 bmap 的地址,dataOffset 代表 key 数组相对 bmap 的地址偏移,加上 i 个 key 的偏移最终得到第 i 个 key 的地址,第 i 个 value 则是 i 个 value 的偏移加上所有 key 的偏移。
如果当前的 bucket 没有匹配的 k-v 对,那么可以使用 b=b.overflow(t) 循环遍历所有相同标号 bucket。
1.1.5 minTopHash
对于 tophash ,计算一个 key 对应的 hash 值后,需要加上一个 mintophash 值,表示对应的 cell 没有发生迁移,可以正常搜索使用。
当一个 cell 的 tophash 的值小于 mintophash,则证明该数值表示的是迁移状态,而非 tophash 值。常见的状态值如下:
| |
在判断 bucket 是否完成迁移时,只需要检查该 bucket 中第一个 cell 的状态值,是否为 evacuatedEmpty,evacuatedX,evacuatedY 中的任意一个。
1.1.6 删除过程
底层执行函数为 mapdelete,针对不同的 key 类型,可能会被优化为更具体的删除函数。
| |
- 检查
h.flags字段,检查写标记位是否为 1,需要保证删除时没有其他 goroutine 在写入 map。 - 计算 key 的 hash,找到对应的 bucket,如果其正处于扩容中(topHash < mintopHash),则直接触发迁移动作
growWork。 - 对当前 bucket 进行两层循环,检查所有 cell,删除对应的 k-v 对。
- 将 hmap 的 count 减一,对应位置的 tophash 值设为 Empty = 0。
1.2 map 的扩容
装载因子:loadFactor := count / (2^B) ,其中 count 表示 map 中的元素个数,$2^B$ 表示 bucket 的个数。
触发扩容的两个条件:
- 装载因子超过阈值,即 6.5,此时 bucket 即将装满,查找效率低下。
- overflow 的 bucket 数量过多,虽然装载因子小,但 bucket 数量多。
扩容方案:
- 元素数量太多,bucket 数量太少,故创建新 bucket,数量为 $2^{B+1}$。
- bucket 内部元素分散,故开辟新的 bucket 空间,将老 kucket 中的元素移动到新的 bucket,排列更紧密。
采用渐进式的扩容策略,每次最多迁移 2 个 bucket。
两层循环:遍历所有的 bucket 和相连的 overflow,每个 bucket 遍历所有的 cell。
1.2.1 hashGrow
hashGrow():分配新的 buckets,将老的 buckets挂载到 oldbuckets 字段上,并处理相关的标志位。
标志位:用于记录迭代器、写操作等,保证扩容的正确性,与 bucket 的一致性。
| |
注意对 h.flag 中 iterator 的操作:新设置的 flag 应先将 h.flag 中 iterator 与 olditerator 的对应位清零,如果发现 h.flag 的 iterator 位为 1,则将其转移到 olditerator 位,与 bucket 一致。
| |
&^运算:设a &^ b,如果 b 的对应位为 1,则结果该位为 0;否则与 a 对应位的值一致。
1.2.2 growWork
growWork():真正的迁移动作,被插入、修改、删除等动作调用,
| |
1.2.3 evacuate
rehash:从老 bucket 迁移到新 bucket,需要检查的最低位数 +1,因此需要重新分配 bucket。
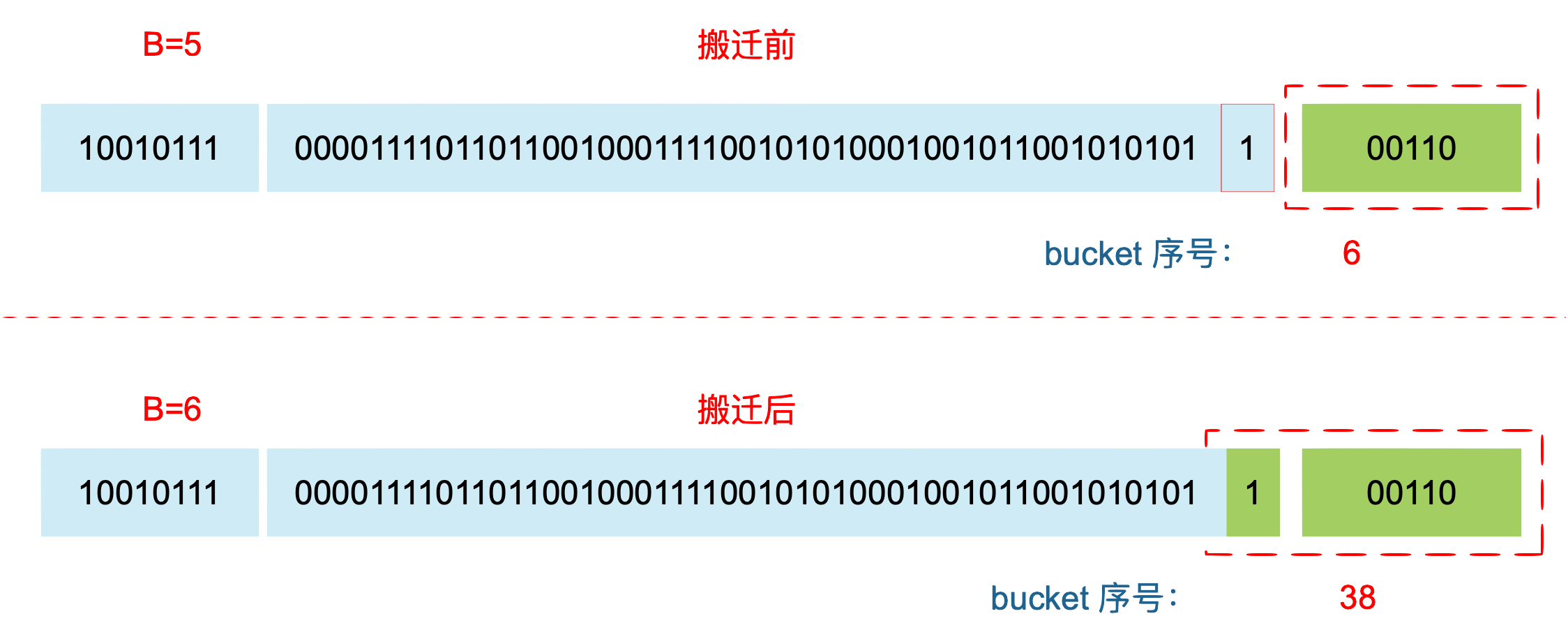
桶的裂变:对于装载因子超过 6.5 的情况,原来处于第 i 个 bucket 的两个值可能进入不同的 bucket,分别是 X part 的 i 号 bucket 和 Y part 的 i + B (B ~ ) 号 bucket。
X part: $0 - (2^B - 1)$
Y part: $2^B - (2^{B+1}-1)$
桶的迁移:对于 overflow 过多的情况,只需要按序号迁移,一一对应即可。
// TODO:evacuate 源码,迁移过程详解,NaN
1.3 map 的使用
1.3.1 取址操作
不可以对 key 或 value 直接取址,通过其他手段(unsafe.Pointer)得到的地址也不能长期持有,因为 map 的扩容会导致该地址失效。
1.3.2 get 操作
分为两种,带 comma 和不带 comma 的读取方法。
| |
如果没有 key 存在,则返回一个 value 类型的空值,ok 为 bool 类型值。
调用 mapaccess 函数,分别返回指针、指针 + bool,针对不同的 key 类型也会有对应的函数进行优化。
1.3.3 赋值操作
调用 mapassign 操作,针对不同类型的 key 同样有优化。
- 首先检查 map 的 flag 的写操作标志位,为 1 则导致 panic,0 则将其置 1。
- 如果当前 bucket 处于扩容状态,进行迁移操作。
- 设置两个指针
inserti和insertk,分别指向 tophash 和 key 的地址,value 可以根据 key 的地址计算获得。 - 检查当前 bucket 以及关联的 overflow,确定所在位置。
- 判断是否需要扩容,如果需要则主动迁移。
- 更新 key 地址的值,如果是新插入的则将
h.count加一,将写操作位置 0。 mapassign函数返回的是 value 的地址,进而对该地址赋值。
将 float 作为 key 存入 map 可能会出现问题,这是由 map 会将 float 转换为 unit64 所导致的精度问题造成的,不同的值会对应同一个 k-v 对。
将 NaN 作为 key 存入 map 一定会出现问题,由于 NaN != NaN,导致 hash[NaN] != hash[NaN] ,故不同的 NaN 会对应不同的 k-v 对,对插入的 NaN 也无法被查找到。
1.3.4 遍历操作
go 的 map 以 bucket 为单位进行遍历,bucket 的顺序是随机生成的,因此基本不可能输出相同的顺序输出。map 中的 key 是无序的。随机生成过程如下:
| |
问题:如果 map 触发了扩容,那么在很长时间内都会处于一个中间态,此时遍历会涉及到新老 bucket 同时存在的问题。
解决方法:
选择一个 bucket 作为遍历 bucket 的起点。
检查对应的原 bucket 是否完成迁移
如果已完成迁移,则遍历原来选择的 bucket;
否则,遍历原 bucket 中应属于新 bucket 部分的 k-v 对
原有 0,1 bucket,扩容过程中 1 裂变成 1,3 bucket,0 尚未裂变。
对于 0,发现 0 未裂变,则检查裂变后属于 0 的部分。
对于 1,发现 1 已裂变,则只需检查 1。
对于 2,发现 0 未裂变,则检查裂变后属于 2 的部分。
对于 3,发现 1 已裂变,则只需检查 3。
1.3.5 比较操作
- 一个 map 只能与 nil 比较,确定是否非空。
- 两个 map 的比较需要遍历比较。
1.4 map 线程不安全
map 是线程不安全的。
在进行增删改查时都会检测
h.flag的写标志位如果正在写则直接 panic;
否则,对于删和改操作,会先将写标志位置 1,然后进行操作。
sync.RWMutex:为读写操作加锁,缺点是大量 goroutine 争夺同一把锁时会造成效率低下。
sync.Map:支持并发读写的 map,冗余设置 read 和 dirty 两个数据机构,减少锁对性能的限制。支持读多写少的情况,写多的情况会导致性能下降。
2 Slice
2.1 Slice 与 Array
Slice 的底层数据是数组,对数组进行封装,描述数组的一个片段。一个数组可以被同时被多个 Slice 指向,因此一个 Slice 的改变可能造成多处影响。
数组的长度是类型的一部分,不同长度的定长数组属于不同的类型,作为函数的参数不能等同。
| |
2.2 Slice 的使用
作为函数的参数,进行 Slice 的值传递
- 对于 Slice 的改变不会影响原数据,append 等只影响函数内的拷贝。
- 对于 Slice 底层数组的改变会影响原数据,直接对 slice[i] 赋值会返回给本体。
| |
2.3 Slice 的扩容
使用 append 函数,返回的是一个新的 Slice,不可以不使用。
- 当
len == cap时,需要扩容,Slice 转移到新的内存位置。
所需容量大于二倍时,直接赋给需要的容量
原容量小于 1024 时,
cap(new) = 2 * cap(old)原容量大于 1024 时,
cap(new) = 1.25 * cap(old)
- 在分配后进行地质对其,因此最终都
≥上述值。 - 向 Go 内存管理器申请内存,将老 slice 中的数据复制过去,并且将 append 的元素添加到新的底层数组中。
- 返回一个新的 slice,这个 slice 的长度并没有变化,而容量却增大了。
3 Slice 与 map
3.1 传参区别
在使用 makemap 函数时,返回的是 *hmap,是一个指针;而 makeslice 返回的是 Slice 结构体。
作为参数发生值传递时:
*hmap仍指向原map,因此函数内部的值发生改变;Slice在函数内被复制,因此函数内部的变化不会影响原Slice。append 等操作不影响,对于底层数组的修改会影响。
3.2 使用
map 的 key 需要匹配一个具有相等属性的类型,Slice 不能判断相等,因此Slice 不能作为 map 的 key 进行查找。